Linux操作系统拿来组织和管理文件的系统是非常复杂的。文件系统是软件层的概念,其底层是可以储存数据的硬件,例如硬碟、U盘、软盘等,要想理解下层的文件系统要从底层的硬件系统来着手,不过作为程序员,不须要了解所有的储存硬件的构造,只须要感受其中的设计理念和了解软件层的构架演化过程。
一、机械硬碟(一)化学结构
传统机械硬碟化学结构
硬碟逻辑结构
传统机械硬碟借助矩形的硬碟来进行数据持久化,每位硬碟上有许多直径不同的圆环,每位圆环上可以觉得存在着一个个的具有磁性的点,每一个磁点在某一刻处于N极或则S极,用于记录1bit数据,这个圆环一般被称为扇区(track)。最内圈的扇区编号为0,从内向内编号递增。
硬碟的上下两面结构是一样的,都可以拿来储存数据,其中心固定于主轴上,可以跟随主轴旋转。在硬碟的上下两面各有一个固定于磁臂上的盘片(header),盘片可以按照其扫过的扇区上的磁点的磁性来形成不同的联通号,借此来判定当前bit是0还是1。
为了便捷数据的低格管理,制造商将磁头界定成一个个的弧形,每位弧形的角度是相同的,储存的数据量也是相同的,默认为512B,这一个弧形一般被称作磁道(sector)。每位磁头上的磁道都有着一个编号,磁头第一个磁道的编号为1。
为了储存更多的数据,一块硬碟中一般有好多个硬碟,每位大盘都配有一个可以读取磁性的盘片,盘片的编号从0开始,从上到下递增,一般以盘片编号来指代具体的大盘。不同大盘上的相同编号的扇区上的相同编号的磁道的集合,被称作柱面(cylinder)。
观察前文中列列举的最早的机械硬碟的化学结构,可以发觉磁道从硬碟的内圈扇区到外圈扇区,磁道的弦长是递减的,而且在设计时她们的容量是相同的,即都是512B。并且因为内圈磁头上的磁道弦长较长,致使其磁性材料的密度较低,浪费容量linux分区查看,所以经过改进,技术人员将磁头界定为了不同的集合。同一个集合内的磁头是相邻的,但是其弧度是相同的,弦长只有细微差别,而不同集合的磁头弦长是相同的,然而弧度不同。
上图所示的硬碟结构中,每一个磁道的容量依旧为512B,内圈扇区的磁道最多,外圈扇区的磁道最少。
(二)、数据查找
通过简单了解了机械硬碟的结构,如今应当可以清楚下边这几个概念:
扇区:track磁道:sector盘片:header柱面:cylinder
接着我们来思索一个问题,硬碟是怎样读取某个特定位置的数据的呢?首先我们要晓得下边两个基本概念:
硬碟有自己的CPU和缓存,其CPU才能在接收到储存或则写入目标地址的指令时,按照固化在硬碟ROM中的代码指令操作机械臂联通,因而才能让盘片联通到目标地址进行数据读写。
硬碟作为一个硬件设备,一般是通过显卡与CPU进行相连,其他的还例如主板、键盘、鼠标等,像这些一般也叫作外接设备。而设备的种类和版本又各类各样,所以操作系统将设备具象成一个个的插口,由设备管理器统一管理。
设备管理器用于管理设备的程序就称作设备驱动器,如右图所示
这样在我们更换了硬件设备以后,只须要再更新一下对应的设备驱动器就可以了,而操作系统本身对于硬件是否更换了是无感知的,属于一种前馈的设计。
这也就是说机械硬碟上的CPU所接收到的指令是由操作系统通过c盘驱动下发的。
在硬碟的CPU接收到c盘驱动下发数据读写的指令后,其中重要的一步就是数据的轮询,其数学意义就是将盘片联通到目标位置。
传统的机械硬碟轮询形式为CHS轮询linux驱动下载,最开始的时侯地址为24位:
Ccylinder柱面前8位编号从0开始
Hheader盘片中间10位编号从0开始
Ssector磁道最后6位编号从1开始
里面参数所代表的意义在后面的早已介绍过,下边来看一个实际的事例:
当机械硬碟的CPU接收到地址0x00000001时,经过CHS的地址转换,可以得到
C=0
H=0
S=1
即目标的实际位置为0号大盘0号扇区的1号磁道,之后就交给硬碟的CPU区控制磁臂将盘片联通到这个位置
不过因为CHS轮询遭到地址位数的限制,轮询空间有限,所以现今通常舍弃了CHS轮询而采用LBA轮询形式。
(三)、硬盘格式
从硬碟的化学结构可以看出硬碟只是二补码数据的一个载体,而二补码数据本身是没有意义的,就是连续的01二补码序列。这么计算机如何能分清什么序列是文件内容,什么序列是空白呢?所以须要将硬碟中的数据以某种格式组织上去,即硬碟的低格,从这我们也才能获知硬碟的格式是软件层面的概念,而不是硬碟本身的属性。传统机械硬碟的数据组织形式通常为MBR格式。
MBR格式的硬碟的第一个磁道储存一张MBR表,其由4个部份组成:
其中比较重要的是下边两个部份:
主引导程序共446字节大小。其主要提供下边功能:
提供菜单:用户可以选择不同的开机项目(例如装了双系统,选择启动那个系统的菜单)
载入核心文件:直接指向操作系统的引导代码所处的硬碟位置
转交其他loader:将开机管理功能转交给其他loader负责,主要用于多系统引导。
主分区表一共64B,单条记录占用16B,最多记录4条数据。主分区表中的每一条记录表示一个硬碟的分区。主分区表中的单个记录格式如下:
在主分区表的单条记录中,一般只须要关注第1、5字节和最后8个字节,其中第5字节代表了分区的类型或则说分区的格式,常见的分区类型如下:
二、硬盘分区
至于哪些是分区呢?可以简单理解为将一块硬碟上的所有硬碟上的所有磁道具象成一个编号从1开始的磁道字段,而分区就是链表中的某一段。之所以要将硬碟的格式设计成带分区的模式,主要有两个诱因:
因为硬碟的转动速率是角速率恒定(CAV)的,这就导致盘片在内圈扇区扫描的速率要远低于外圈扇区,所以操作系统的代码通常置于内圈扇区上进行储存。回想一下,我们小时候是不是都据说过系统盘C盘比较快的传言。
因为传统硬碟的使用是从内向内的,即在写入新数据时,会优先写入储存较快的区域。并且有些无关紧要的数据,我们不想让他占用读写较快的区域,这个时侯就要给无关紧要的数据指定读取速率较慢的储存区域,将有读写速度要求的数据和无关紧要的数据隔离开来。
硬碟还有一个用处就是可以给不同的分区设置不同的数据结构,以应对不同的业务场景。例如索引结构的分区适宜储存查找较多的数据,而线性结构的分区适宜储存插入较多的数据。
分区可以分为三种类型:主分区、扩展分区、逻辑分区
因为MBR格式在设计时,只给主分区表保留了64B的空间,而主分区表中的每一条记录要抢占16B,所以最多才能直接记录4个分区。这四个在主分区表中直接定义的分区就是主分区。
随着计算机的应用场景越来越复杂,四个分区是肯定没法满足所有需求的,于是提出了扩充分区的概念。
主分区最多有四个,最少有一个,而扩充分区最多有一个,也就是说一个操作系统中只能有下边几种分区组合方案:
1个主分区
2个主分区
3个主分区
4个主分区
3个主分区+1个扩充分区
记录扩充分区的主分区表项中记录了扩充分区所占有的所有磁道信息。
扩充分区的主要功能是为了突破MBR格式的硬碟最多只能有4个主分区的限制,所以扩充分区又可以分成许许多多的逻辑分区。
同MBR表中的主分区表一样,扩充分区中的逻辑分区也须要一张分区表来进行磁道界定。所以在扩充分区的第一块磁道中,存在一张EBR表,不仅没有MBR表开头446字节大小的主引导程序,剩下的逻辑分区表和结束标记与MBR相同,但是逻辑分区表并没有16B的限制。
上述的概念听上去可能不容易理解,下边通过一个实际的反例来剖析一下MBR和EBR表。
操作系统:windows10
打开我的笔记本->管理->c盘管理,可以看见c盘1目前的分区状态
此时笔记本上早已有了两个主分区:D和E
下载工具winhex,并了解其简单使用方法:
winhex下载
winhex教程
在winhex中打开化学硬碟,可以查看硬碟的二补码数据
查看硬碟的第一块磁道,即MBR引导磁道,白色部份就是主分区表:
主分区表中一个分区记录项占用16B,当前主分区表中只有前32B有数据,即只记录了D盘和E盘两个主分区,简单来剖析一下D盘:
第1个字节0x80,表示这是一个活动分区
第5个字节0x07,表示这是一个NTFS格式的分区
第9、10、11、12个字节表示当前分区的起始磁道,不过要注意下这是小端序,实际为0x00001000,十补码为4096
第13、14、15、16个直接表示当前分区一共有多少磁道,同样为小端序,实际为0x1D201000,十补码为488640512
而E盘是紧跟随D盘的,所以E盘的起始地址为0x1D202000,十补码为488644608,经过简单的估算就可以看出488644608=488640512+1096
下边先来创建一个扩充分区,首先将E盘压缩一下,得到2GB的空闲空间
之后在未分配空间上右键新建简单卷,一路点击下一步,可以发觉又创建了一个主分区
之后在未分配的卷上再创建一个简单卷,可以看见发生了变化
未分配空间默认弄成了扩充分区,新加卷G弄成了扩充分区中的一个逻辑分区,通过winhex查看此时硬碟的分区信息,可以看见多下来几个分区:
首先还是查看一下MBR中的主分区表,如今主分区表中的四个表项早已被塞满了,其中第四个表项为扩充分区表项:
通过第五个字节0x0F,表明当前主分区表项记录的是扩充分区
通过最后8个字节可以估算出该扩充分区起始磁道为0x3A097000(973697024),一共包含0xx002002EE800(3074048)个磁道
而973697024这个磁道就是EBR表所在的磁道
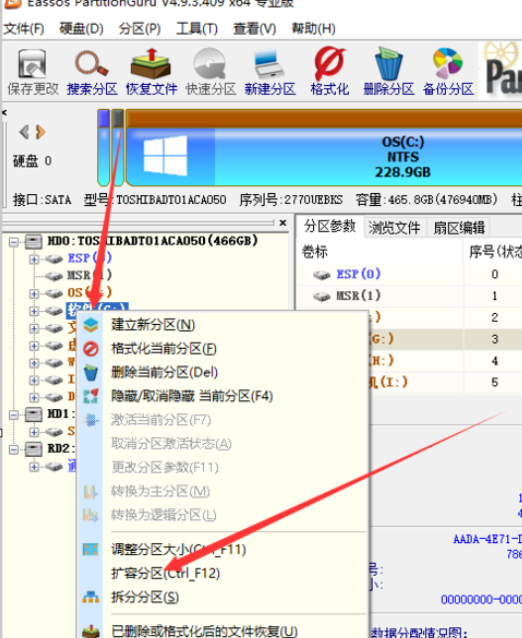
查看其内容可以看见此时只有第一个16B被使用了,即此扩充分区只有一个逻辑分区G
逻辑分区的第五个字节0x07表示当前逻辑分区的类型为NTFS,最后八个字节表示该逻辑分区的起始磁道和磁道总量。
不过与MBR中的主分区表不同的是,EBR中的分区表的起始磁道是相对于扩充分区的起始磁道的偏斜量,下边是简单估算:
起始磁道为0x00000800(2048),磁道总量为0xx000000FA000(1024000),因为2048是偏斜量,扩充分区的起始磁道为973697024,所以逻辑分区G盘的起始磁道为973697024+2048=973699072,和上面用红框标下来的检查结果相同
在了解了前面的概念后,很容易画出硬碟分区的结布光:
三、Linux文件系统
linux是开发者最常用的操作系统,其有一个重要的设计理念就是一切皆文件。Linux的文件系统是作为一名开发者必需要把握的知识点。例如:
(一)、Linux硬碟分区
同Windows一样,Linux中同样支持MBR格式的硬碟分区。硬碟在Windows中作为一个设备插口,Windows通过c盘驱动器与其进行交互,在Linux中同样这么。不过因为Linux中一切接文件,所以这个设备插口是以文件的方式存在的。
无论是实体设备例如硬碟还是虚拟设备如云复印机,其设备插口文件都存在与/dev目录下,实体设备插口文件的一般名子为sd[a-z],虚拟设备插口文件的一般名子为vd[a-z]。
以实体设备硬碟为例:
形如sda1、sda2、sda3....sdan的文件,就是硬碟sda的分区了,类似于Windows系统中的D、E盘的概念。
可以通过下边命令查看Linux中的硬碟设备和硬碟分区情况:
fdisk-l
从显示信息可以看出当前Linux操作系统只有一块总容量32.2GB的硬碟,一共包含62914560个磁道,每位磁道为512B,且该硬碟有三个主分区sda1、sda2和sda3
对比一下Windows系统下的分区,不仅有设备驱动文件之外,每位分区还关联了一个称作c盘的东西,如下边的D、E、F、G
当在Windows中访问C://开头的资源时,操作系统有依据c盘就能否晓得目标资源实际坐落那个分区。
同样的Linux中也有类似于c盘的东西,一般被称作挂载点。使用下边命令可以看见Linux中的所有挂载点:
df-lh
如同结果所显示的那样,Linux是直接将路径和分区进行关联的,例如/boot目录下的所有数据都储存在硬碟sda的1号分区中。
Linux中可以通过下边命令查看硬碟分区的格式:
df-T
红框圈下来的Type列就是分区对应的格式,如硬碟sda的1、3号分区的格式都是xfs,Linux中常见的格式有xfs、ext2、ext3、ext4等。
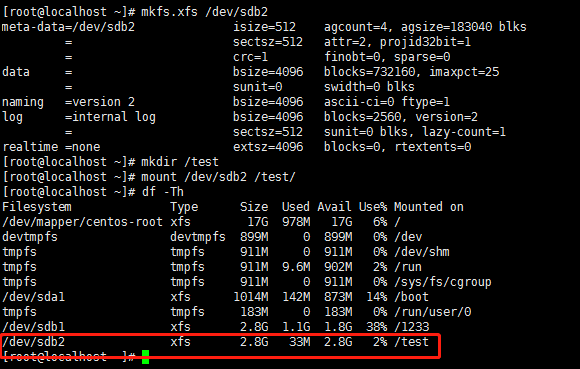
至于Linux的分区实战,直接看下边实战就好
linux硬碟分区
假如将Linux硬碟分区的步骤对比到Windows硬碟分区如下:
新加卷大小->分配磁道数目
选择分区格式->低格分区
生成c盘->将分区挂载到某个目录(二)、常见Linux硬碟分区格式——ext2硬碟布局
Linux中常见的硬碟分区格式有xfs、ext2、ext3、ext4等。假如将硬碟本身被具象为一个数据库房linux操作系统安装,则硬碟分区可以看做库房中的一个个仓库,而有的仓库拿来储存小件物品,数目较少只须要次序摆放,而有的仓库拿来储存大件物品,数目较多,须要使用货架而且要更细致的编号。硬碟的分区的格式,就可以称作仓库是怎样记录和摆放货物的方案。
以ext2格式为例,了解一下硬碟分区格式的基本概念:
ext2分区格式结布光
里面早已介绍了硬碟的化学储存单元为磁道,而分区的储存单元是由1个或则多个磁道组成的逻辑储存单元,一般被称为block(块)。block的大小可以在分区低格的时侯由操作者指定,一般为1024B或则4096B,转换成磁道一般就是2个磁道或则8个磁道大小。其实同是ext2格式的不同分区,block的大小可能不同,而且同一个分区内的所有block的大小一定是相同的。
bootblock(引导块)是坐落分区最开始的一个block,可以拿来储存类似于硬碟惟一的MBR表中bootloader,即一般被用于在同一个计算机中安装多个操作系统。
blockgroup(块组)是ext2分区格式中用于组织和管理block的逻辑界定。每位blockgroup由superblock(超级块)、GDT(groupdescriptortable组描述符表)、blockbitmap(块位图)、inodebitmap(索引节点位图)、inodetable(索引节点表)、datablocks(数据块区)组成。之所以界定blockgroup,可以理解为仓库太大,将仓库界定成了几个类似的区域分别管理。
superblock(超级块)是坐落每位blockgroup的最开始的一个block,其用于描述当前blockgroup所在分区的元数据信息,例如每位block的大小、block的总数目、空闲可用的block数目等。
superblock部份内容
GDT坐落superblock以后,一般抢占连续的n(>=1)个block。GDT中主要保存了当前blockgroup的元数据,主要当前blockgroup中其他部份的表针以及block数目相关信息:
GDT部份内容
blockbitmap(块位图),其本身抢占一个block的大小,记录当前blockgroup的datablocks区域中什么块是早已被使用的,什么块是未被使用的。blockbitmap将datablocks区域中所有块以线性地址组织上去啊,每一个块用一位来记录信息,例如块位图有1024B,则一共有1024*8=8192bit,则其最多能记录8192个block的使用情况。如果当前blockbitmap状态为10..........(8190个0),则说明datablocks区域中,只有第一个block被使用了,其他的都是空闲状态。
inodebitmap(索引节点位图),本身抢占一个block大小,功能类似于blockbitmap。inodebitmap用于记录inodetable区域中什么inode是早已被使用的linux分区查看,记录方式和blockbitmap相同。
inodeTable(索引节点表)中包含了须要indoe,每位inode记录了文件的元数据,例如文件类型,权限,文件大小等(没有文件名),即通过
ls-l
命令可以查看的内容都是记录在inode上的。系统中的每一个文件都可以找到一个inode与与之对应,一个inode本身大小一般是128B或则256B。inode中还储存了与其相关的block的表针,以易于通过inode可以快速取出当前inode对应的文件的所有储存在block中的数据。
datablocks(数据库区域)就是一组逻辑上连续的block的链表,主要拿来储存文件的数据部份。在进行文件储存时,一个block只能被一个文件持有,即只能被一个inode所关联。虽然block默认为1KB,并且文件只有1B大小,该文件仍然会独占当前block空间,另外999B会浪费掉。
在简单了解了ext2格式的硬碟布局以后,我们起码可以晓得,在硬碟分区设置inode数目时,要结合实际的场景来进行设定。如果当前分区更多的拿来储存小文件,则最好将block设置的小一点,inode的数目设置的多一点,以免发生inode数目不足或则大量浪费硬碟空间的情况。如果当前分区更多的拿来储存大文件,则可以将block设置的大一些,inode的数目此时可以相应的少一些。
(三)、虚拟文件系统——VFS
既然硬碟可以有如此多种分区格式,如果我要将数据从A分区复制到B分区,Linux是怎样将数据在两种不同格式的分区之间快速转换的呢?Linux又是怎样为操作系统的使用者屏蔽掉分区的细节,因而让使用者无需关注分区信息的呢?这就是Linux的虚拟文件系统的作用。
VFS构架图
从VFS的构架图可以看见,其作为一个黑盒,向Application(应用)提供了统一的文件操作插口,例如读取数据的read插口、写入数据的write插口、修改权限信息的chmod插口等。而VFS本身除了兼容了个各类硬碟分区格式,还兼容了proc、sysf、ramfs等显存文件系统。总而言之,对于Linux的使用者来说,可以将整个Linux看做只有一块大的化学储存介质,而这个储存介质只有一个分区,分区格式为VFS
作为一个文件系统,VFS肯定也要有自己管理和组织数据的形式,要想了解VFS的原理,首先从其基本数据结构来看
superblock(超级块),倘若上面的内容你仔细看了,一定就能回想上去,ext2分区硬碟布局一节中有提及过,每位blockgroup中第一个block就是superblock,其记录了所在分区的一些基本元数据。VFS中同样有superblock的概念,其用于储存早已注册的硬碟分区的信息(例如该分区是哪些格式、容量大小等)以及分区挂载的目录,分区的所有inode,以及VFS中数据操作单元block的大小。VFS里的inode和block与具体的硬碟分区格式中的inode和block还是有区别的,VFS的inode和block通过相应分区格式所对应的硬碟驱动程序可以和硬碟分区本身的block和inode进行转换。可以觉得VFS中一个superblock就对应着一个分区,或则说一个分区的文件系统
vfs-super_block
inode(索引节点)用于描述储存文件信息,一个inode就代表一个VFS中的文件。不同的硬碟分区格式都有着自己不同的代表文件的数据结构,可能也叫作inode(例如ext2、ext3等),也可能不叫作inode。VFS所做的工作就是将所有兼容的分区格式的表示文件的数据结构进行具象和统一,将不同硬碟分区的文件数据结构转换成VFS的inode节点,但是将属于同一个分区的inode节点组织成一条数组
这个动作也可以说是使用硬碟中的inode填充VFS中的inode。VFS-inode和硬碟inode有些性质是相同的,例如一个文件只对应着一个VFS-inode。另外须要注意的是,在Linux上一切都是文件,虽然是目录也是一种特殊的文件。
VFS-inode中并没有直接记录文件在硬碟分区上的block的具体位置,而是只记录了在VFS中的起始block、占据block、以及最后一个block中的数据大小:
Linux中通过不同的挂载点来分辨不同的硬碟分区,通过VFS-inode将文件和文件在c盘中的indoe进行相关联。
然而对于操作系统用户来说,我们不可能通过inode的编号来访问文件,我们只能按照文件名来操作文件。为了将文件名和文件的VFS-inode做映射,所以有了dentry的概念。
另外多个dentry可能对应于同一个inode,这也是Linux中链接的实现原理
假如将dentry和inode理解为编程中的Class,而file就是对象的概念。dentry和inode储存的都是文件的元数据,是所有进程锁共享的,而file拿来表示一个进程打开了某个文件,以及该进程有什么操作权限,当前读取偏斜量等进程私有数据。
四、Linux进程和文件
在了解了VFS的基本概念以后,最后须要简单了解一下进程和文件直接的关系。
Inodetable,索引节点表,上面早已介绍过,保存了VFS中的所有inode。
每每文件被进程打开一次(open系统调用),就会在内核的打开文件表中添加一条表项。该表项中主要记录了此次打开文件的读取偏斜量、文件对应的VFS-inode节点表针等
同一个文件可能被不同进程打开多次,每次被打开就会在打开文件表中形成一个表项,但这两条打开记录所指向的VFS-inode是同一个:例如记录0和86
而同一个进程打开文件多次,则在打开文件表中只会有一个表项:例如记录23
每位进程中都保存了一个指向打开文件表表项的文件描述符表
每位文件描述符表的表项中记录了文件描述符、文件打开标志(进程级别的读写权限)、指向打开文件描述符表的表项的文件表针。
同一个进程打开同一个文件多次,则在文件描述符表中会有多条记录,即持有多个文件描述符,然而在打开文件表中只会有一个记录:例如记录fd1和fd30
不同进程的文件描述符表的记录也是有可能指向相同的打开文件表记录的,例如进程A的fd2和进程B的fd2,她们都指向打开文件表73,这些情况主要有两种可能:
1、B和A进程为兄妹进程
2、B和A之间共享变量
通常情况下不会形成这些现象
五、一些操作的基本命令
查看当前系统的所有挂载点信息,例如硬碟分区格式,VFS的block大小,inode使用情况
df-l
详尽的硬碟分区格式可以通过下边命令查看
fdisk-l





